Thank you for submitting your request.
We will get back to you shortly.

Share your requirements and we'll get back to you with how we can help.
Based in Europe, our client is a leading IT consulting firm that offers software development and implementation as well as solution integration. The client needed an advanced forecasting system to predict consumption rates of electricity and gas.
QBurst developed machine language models based on various regression algorithms to predict gas and electricity consumption demand.
Machine learning helps garner insights by creating models that use various algorithms to iteratively learn from data without being programmed. Analysis of insights and patterns found using an analytic model creates business value when executing the model on future events in real-time. Our client was able to capture insights on energy usage, grid optimization, demand forecast, and load management in order to improve conservation strategies. It would also be possible to develop interfaces to monitor systems and attend to outages even before they occur. As these machine learning algorithms are self-correcting, they get more accurate over time.
Other use cases include optimized pricing, promotions, cross-selling, traffic management, inventory forecasting, and preventive maintenance.
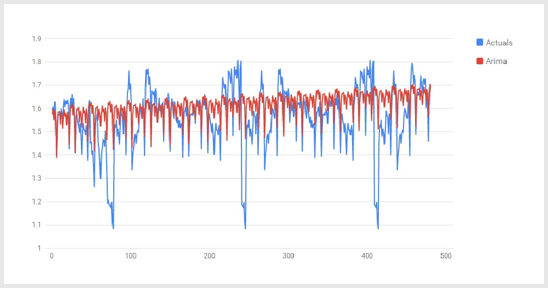
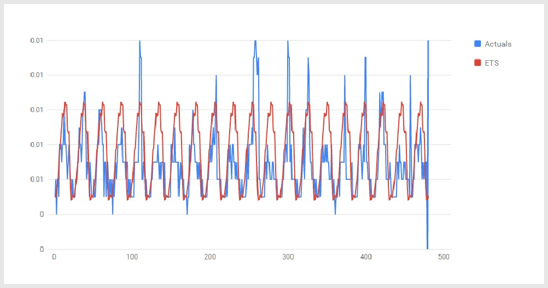
QBurst developed Azure ML models using various regression algorithms such as Seasonal Autoregressive Integrated Moving Average (SARIMA), Exponential Smoothing, and Decision Forest. These were trained based on historic data of electricity and gas consumption. These models were then repeatedly tested for accuracy by scoring and retraining, later fine-tuned, and refined several times to improve accuracy of predictions.
The Process
Analytical Model Building: Vast amounts of operational data was collected and stored for analysis. Data was acquired by integrating relevant data sources. Different datasets were merged and analyzed to gain valuable insights while historic data was used to build analytical models. Our data scientists used the output of data preparation for extensive analysis to create models that delivered insights.
Analytical Model Validation: 90% of the data was first used to train the machine learning algorithm. After this, the remaining 10% was used to validate the model. The models were then fine-tuned by changing parameter values in algorithms and the process repeated until the model scored a high level of accuracy between the predicted and actual values.
Analytical Model Retraining: The predicted values for any given input was recursively used as input for training, thereby continuously retraining the model on an ongoing basis.
QBurst developed machine language models based on various regression algorithms to predict gas and electricity consumption demand.
Machine learning helps garner insights by creating models that use various algorithms to iteratively learn from data without being programmed. Analysis of insights and patterns found using an analytic model creates business value when executing the model on future events in real-time. Our client was able to capture insights on energy usage, grid optimization, demand forecast, and load management in order to improve conservation strategies. It would also be possible to develop interfaces to monitor systems and attend to outages even before they occur. As these machine learning algorithms are self-correcting, they get more accurate over time.
Other use cases include optimized pricing, promotions, cross-selling, traffic management, inventory forecasting, and preventive maintenance.
Based in Europe, our client is a leading IT consulting firm that offers software development and implementation as well as solution integration. The client needed an advanced forecasting system to predict consumption rates of electricity and gas.
QBurst developed Azure ML models using various regression algorithms such as Seasonal Autoregressive Integrated Moving Average (SARIMA), Exponential Smoothing, and Decision Forest. These were trained based on historic data of electricity and gas consumption. These models were then repeatedly tested for accuracy by scoring and retraining, later fine-tuned, and refined several times to improve accuracy of predictions.
The Process
Analytical Model Building: Vast amounts of operational data was collected and stored for analysis. Data was acquired by integrating relevant data sources. Different datasets were merged and analyzed to gain valuable insights while historic data was used to build analytical models. Our data scientists used the output of data preparation for extensive analysis to create models that delivered insights.
Analytical Model Validation: 90% of the data was first used to train the machine learning algorithm. After this, the remaining 10% was used to validate the model. The models were then fine-tuned by changing parameter values in algorithms and the process repeated until the model scored a high level of accuracy between the predicted and actual values.
Analytical Model Retraining: The predicted values for any given input was recursively used as input for training, thereby continuously retraining the model on an ongoing basis.